
The Shopify Operator's AI Chatbot Evaluation Sheet: 10 Tests You Can Score Before You Pick

A Shopify AI chatbot evaluation sheet exists because most stores commit in a ninety-minute demo and find out twelve thousand conversations later that the bot hallucinates the returns policy and back-translates the catalog name into something nobody recognizes. Updated May 2026, this is the ten-test scorecard I would run against any shortlist vendor before signing, scoreable in two hours from the App Store listing, the public demo, and one sales call.
I would rather walk a store through a structured evaluation than ship the prettier demo and rebuild after the third escalation thread. The cost of a wrong pick is rarely the subscription. It is the support backlog, the catalog rewrites that paper over a translate-API failure, and the conversions the operator never recovers. The broader case for AI on the support stack lives in the support-cost-reduction pillar ; this post is the sheet to run before picking the vendor.
Ten tests, zero to three points each, max thirty. Every test names a failure mode, scores from public surfaces, and reaches a decision before any contract is signed.
How do you score a Shopify chatbot you have not installed yet?
The evaluation sheet is a thirty-point rubric across four categories: operational behavior, coverage, commercial fit, and merchant proof. Score each test zero to three. Twenty-four or higher is a pilot candidate. Fifteen to twenty-three is hold-and-extend. Under fifteen, disqualify.
The three input surfaces are the vendor’s Shopify App Store listing, the public demo URL, and one sales call you can schedule in under thirty minutes. Alhena.ai’s post-install stress-test framework runs against three weeks of live traffic; this sheet runs before the install. The comparison-hub listicle tells you which vendors are on the shortlist; the sheet tells you which one earns the pilot.
Operational tests: latency, hallucination, escalation (Tests 1 to 3)
Operational tests catch what fails in the first sixty seconds of a real shopper conversation, whose turn-by-turn structure is mapped in the anatomy of a Shopify chatbot conversation . Latency decides whether a customer waits or leaves. Hallucination decides whether the answer is one your team will spend Monday morning unpicking. Escalation decides whether the bot hands off cleanly when it has lost the room. The public demo runs all three in ten minutes.
Test 1. Demo latency (max 3 points). Ask the demo a product question that needs catalog retrieval, not a scripted FAQ. Whether the bot answers from live retrieval or a stale snapshot is the four-architecture question behind “trained on your catalog” . Time the first token. Under two seconds, three; two to four, two; four to eight, one; beyond eight, zero. A four-second pause on mobile checkout is a reason to close the tab.
Test 2. Hallucination on the live demo (max 3 points). Ask three out-of-catalog questions: invented product names, warranty questions about them, and shipping rules for regions the store does not serve. Three if the bot admits it does not know. One if it invents a plausible answer. Zero if it invents and cites a fake source. The twenty-three thousand conversation dataset shows the long-tail cost of hallucinated returns policy at scale.
Test 3. Escalation logic (max 3 points). Ask the demo a question outside its scope, then ask, “Can I speak to a human?” Three if the bot routes cleanly with conversation context. One if it routes to a contact form with no context. Zero if it loops the scripted “I am an AI assistant” answer. Alhena runs this at week one with a real customer base; we run it on day zero with the demo.
The Shoply public demo answers from the actual product list rather than a curated FAQ; use it as the calibration reference when you score the shortlist.
Where do vendor claims break between marketing copy and the catalog? Coverage tests 4 to 6
Coverage tests catch vendors who claim feature parity and break at the catalog edge two months in. Language coverage decides whether non-English shoppers get answered in their actual language or in something a translate API printed at runtime. Catalog scale decides whether the highest plan fits your SKUs, let alone three years of growth. Schema discipline is the indicator nobody scores: a vendor that ships no structured data for its own homepage will not ship it for yours.
Test 4. Language coverage (max 3 points). Type a product question in the language of your top non-English market: Dutch, German, or French for most stores. Three if the reply matches the buyer’s language and the catalog name keeps its original spelling. One if the reply is in the buyer’s language but the catalog name is mangled. Zero if the bot falls back to English. The failure modes are in the multilingual chatbot guide and the field notes on twenty-three languages .
Test 5. Catalog scale ceiling (max 3 points). On the vendor’s pricing page, find the highest plan’s product cap. Three if the cap exceeds your eighteen-month projection by ten times. One if it covers current count but not the projection. Zero if you need a custom plan to fit. Shoply handles catalogs over one million products natively, the kind of ceiling that lets a merchant grow without renegotiating.
Test 6. Schema discipline (max 3 points). View-source the vendor’s homepage. Search for application/ld+json. Three if Organization, SoftwareApplication, and FAQPage schemas are present. One if Organization is present alone. Zero if nothing is present. AI Overview and Perplexity cite content with structured data; a vendor that ships no schema for its own marketing site will not ship it for yours.
Commercial tests: pricing, install effort, real-merchant proof (Tests 7 to 9)
Commercial tests catch vendors whose cost model collapses at scale, whose onboarding burns more hours than marketing claims, or whose review history hides a recent failure. A shortlist of five usually thins to two through this category.
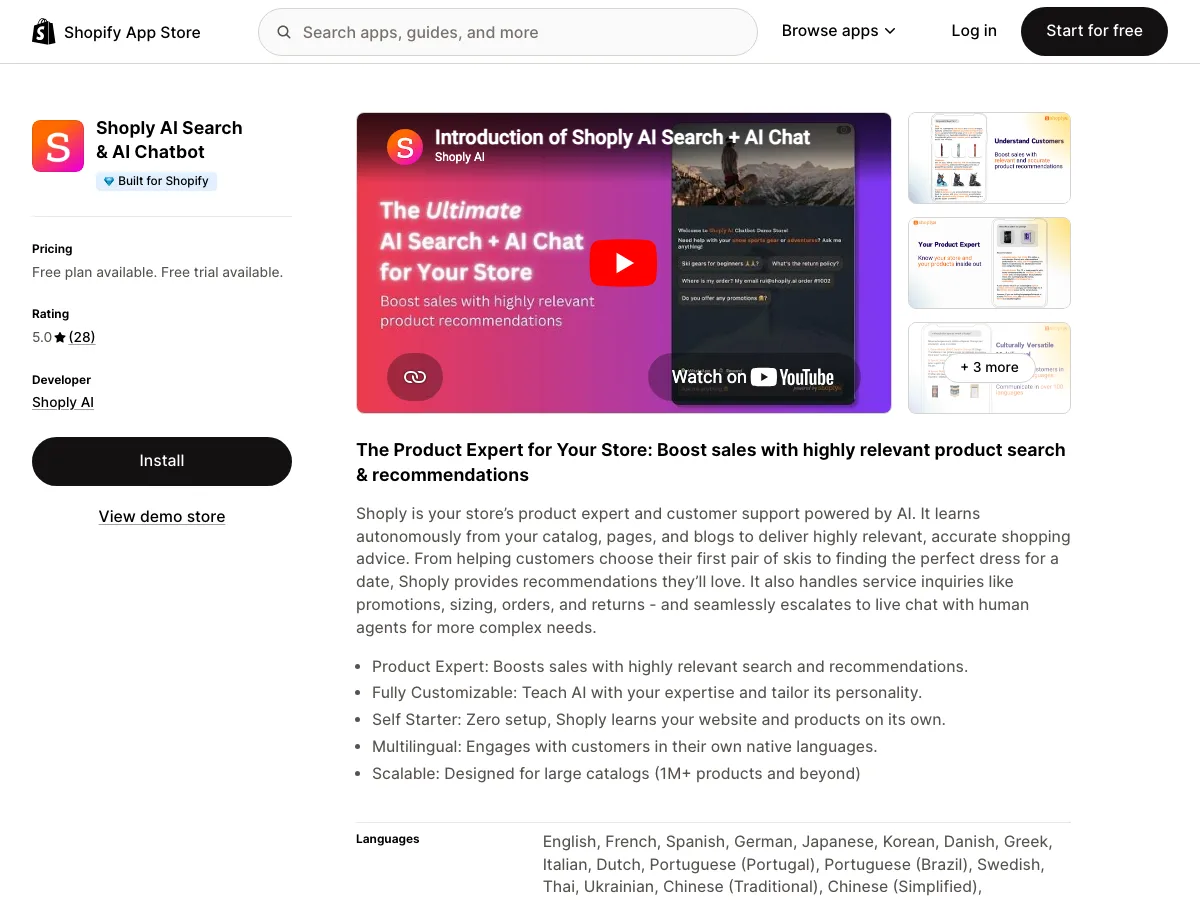
Test 7. Pricing predictability at three times volume (max 3 points). Multiply your monthly conversation count by three and find the resulting tier on the pricing page. Three if the tier is flat-rate and disclosed. One if your volume triggers a “contact us” custom plan. Zero if the cost includes uncapped per-conversation overage. Tidio’s Lyro AI add-on at thirty-nine dollars a month sits on top of the base subscription; Rep AI ships session-based pricing from ninety-nine dollars rising unpredictably with traffic. See the Rep AI alternative breakdown .
Test 8. Install-to-first-reply latency (max 3 points). Read the vendor’s App Store description. Three if “zero setup” appears with no required configuration step. One if a knowledge-base import is required. Zero if a dedicated implementation call is required to go live. Shoply’s autonomous learning ingests catalog, pages, and blogs without an import step; what zero-setup looks like for non-Shopify sites is in the add-anywhere chatbot guide .
Test 9. Review quality, not review count (max 3 points). On the vendor’s Shopify App Store page, sort by lowest. Read the recent five one-star reviews. Three if complaints describe onboarding friction or feature requests. One if they cite billing or support disputes. Zero if they cite hallucination, refund battles, or undelivered promises. Gobot’s rating collapsed from 4.6 to 3.2 last year; the one-star tail tells the story the average score does not.
What does named-merchant proof actually look like, and why is it the deciding test?
The deciding test asks for live operating evidence: no case-study PDF, no testimonial slide, no recorded webinar. A twenty-minute call with a Shopify merchant of comparable GMV running the bot in production for six months or more. A vendor that cannot produce one named-merchant call is selling a demo, not a runtime.
Test 10. Named-merchant proof under load (max 3 points). Email the vendor’s sales team. Ask whether they can set up a twenty-minute call with a Shopify merchant in your GMV bracket running the bot in production for six or more months. Three if a real call is offered within two weeks. One if a written testimonial PDF is offered. Zero if the request is declined or ignored. Shoply’s named installs include Sports Basement (Bay Area sporting goods, omnichannel inventory), IPcam-shop (Dutch security cameras, mixed-language traffic), and Puffo Sport (Italian sporting goods, customers mistake the bot for a human agent). Three named, reachable references is the floor.
Most shortlists do not die because vendors lie. They die because the operator never asks the questions whose answers the vendor cannot fake. A pricing page can fake feature parity. A demo can fake hallucination resistance for ten queries and break on query eleven. A live merchant call is the one piece of evidence that cannot be staged on a marketing site; it is the test the sheet exists to surface.
Sibling read on the search side: chat and search should share an ingestion layer .
Frequently asked questions
How long should this evaluation take per vendor?
Two hours, including the named-merchant-proof email and one follow-up. Tests one through six score in under forty-five minutes against the demo and the pricing page. A shortlist of five vendors fits in one working day.
What if a vendor refuses the named-merchant proof call?
That is a zero on test ten and almost always disqualifying for stores over a thousand SKUs. A vendor whose customer base cannot produce one live reference for a six-month install does not have the operating evidence the sheet is designed to find.
Does Shoply pass its own evaluation sheet?
Shoply ships a 5.0 rating across twenty-nine reviews, twenty-three plus language detection, one million plus product catalog support, a “Built for Shopify” badge, and three named-merchant references (Sports Basement, IPcam-shop, Puffo Sport). Score the sheet yourself; the point is that you do not have to take any vendor’s word, including ours.
Run the sheet, then come back
If you want a calibration point for what a three-point answer looks like on every test, the public demo and the Shopify App Store listing carry the review-quality, schema, and pricing reads the sheet asks for. The companion support-cost-reduction pillar walks through the operator math behind every test. Happy testing.