
AI Search at Scale: What Breaks Past a Million SKUs
AI product search that looks flawless on a 1,000-product demo degrades along four measurable axes once a catalog crosses roughly 100,000 SKUs, and every one of those failures stays invisible until a shopper hits it first. The demo never fires them because a small catalog is small enough that approximate retrieval behaves like exact retrieval. (Updated: June 2026.)
Here is the claim I will defend: the retrieval that passes the demo is the same retrieval that breaks quietly at scale. The demo is built small precisely so the breakage never shows.
An operator should see the four axes before they sign, not three months after the catalog grew. Nobody gets an alert when it slips. The bot just gets vaguer, and the conversion math gets worse with it.
What follows is the runtime view, not the demo view. It is the scale counterpart to a question we have answered before, and it sits inside our wider look at AI search for Shopify .
The numbers here are drawn from running retrieval across large Shopify catalogs. A failure means the right product exists but the system does not put it in front of the shopper.
Why retrieval that aced a 1,000-product demo misses at 1,000,000
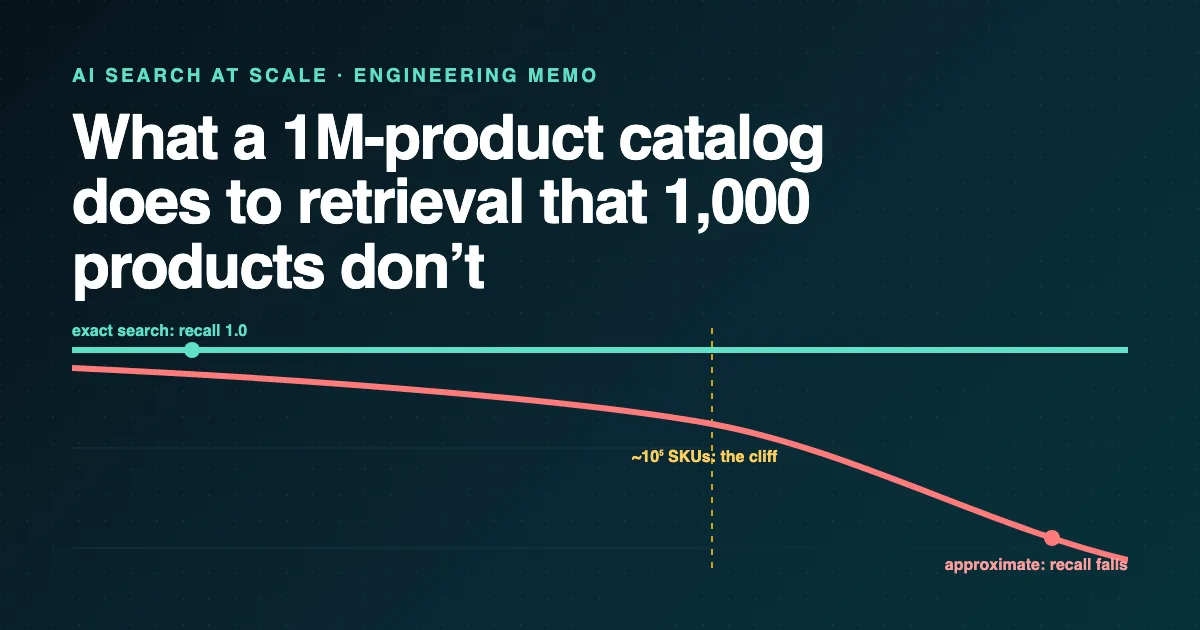
Exact search returns every right product (recall 1.0), but its cost grows with the catalog. So at scale you switch to an approximate index like HNSW or IVF to keep latency flat.
That switch is where recall drops to roughly 0.5 to 0.95 at a fixed latency budget. The right product is increasingly present in the index but never retrieved, and the shopper sees a confident, incomplete answer with no way to tell.
The mechanism is a budget problem, not a bug. An approximate index visits a fixed number of cells per query to hold its latency target.
Grow the catalog a thousandfold and that same budget reaches a thinner slice of a denser index, so the neighbor you needed sits just outside the visited region. Present but not retrieved is the whole failure in three words.
- Exact (flat) search: recall 1.0, cost scales with catalog size. Fine at 1k, ruinous at 1M.
- HNSW / IVF approximate indexes: flat latency, recall in the Pinecone benchmark band of roughly 0.5 to 0.95 depending on how hard you push the speed knob.
- The tradeoff is not optional. Speed versus recall is the central FAISS design tension , documented for years.
A methodology note before the numbers travel: that 0.5-to-0.95 band is the general ANN literature, measured on fixed million-vector benchmark sets, not a Shoply figure. We do not publish a recall number at 1M.
What we will say is the capability claim. Shoply supports catalogs of 1M+ products, and the combined retrieval layer is built to hold recall as the catalog grows rather than quietly trading it away.
What happens to the embedding neighborhood when you 1000x the catalog
At 1,000 SKUs products are sparse in embedding space and easy to separate, so cosine similarity does its job and the top-k comes back clean.
At 1,000,000, variants and near-identical SKUs crowd the same neighborhood. Similarity stops discriminating, and the top-k fills with near-twins instead of the one right answer. The search did not fail; it returned a dozen products that are all almost-correct, which is its own kind of wrong.
A high-variant vertical makes this vivid. IPcam-shop, a Netherlands security-camera retailer we work with, carries families of cameras that differ by a mount, a firmware revision, or a single spec line. (We are describing the shape of that catalog, not a recall figure for it.)
Shopify models those differences as variants, and its own Search and Discovery docs treat each as separately searchable, so those near-identical SKUs sit almost on top of each other.
Type “outdoor 4k camera” into a catalog shaped like that and a generic embedding model hands back a top-5 whose distances barely separate:
- Pro 4K Outdoor Cam, white, PoE (0.971)
- Pro 4K Outdoor Cam, black, PoE (0.972)
- Pro 4K Outdoor Cam, white, Wi-Fi (0.974)
- Pro 4K Outdoor Cam v2, white, PoE (0.977)
- Dome 4K Indoor Cam, white (0.982)
(Illustrative of a generic embedding model on a high-variant catalog, not a Shoply measurement.) Four of those five are the same camera in a different finish or mount, and the one genuinely different result is the indoor dome. The shopper wanted one camera; ranking handed back the product family, because the distances are too close together for cosine similarity to break the tie.
- Sparse catalog: distinct products, distinct neighborhoods, ranking discriminates cleanly.
- Dense catalog: near-duplicates collapse into one region, and the top-k is a pile of twins.
- The fix is not a bigger k. Returning more near-identical results makes the shopper’s job worse, not better.
This is the same vocabulary-and-meaning problem we walk through in the Shopify search synonyms trap , pushed one layer down into the vector index. Shoply’s zero-setup autonomous learning and reranking run over a combined index precisely so that crowded neighborhoods get resolved by meaning rather than by a hand-tuned tiebreak.
How a big catalog quietly hides most of itself
Popularity and interaction signal concentrate on a few head products. The millions of SKUs in the tail get thin clicks and weak learned signal, so they rarely surface.
A larger catalog therefore becomes less discoverable per SKU, the exact opposite of what a merchant expects when they add inventory. More products on the shelf, less of each one reachable.
The shape is a power law, and it is unforgiving. A few thousand head SKUs carry most of the clicks, orders, and reviews that any ranking model learns from. Everything past that shares the scraps.
The tail is not junk inventory; it is real product the system has barely been taught to find.
- Head SKUs get reinforced every day and rank easily.
- Tail SKUs get sparse signal, so their embeddings stay weak and generic.
- The result compounds: weak ranking means fewer impressions, which means even less signal next month.
The mitigation is to learn the tail without waiting for a human to hand-tune it, which is what zero-setup autonomous learning is for.
Keeping those tail answers correct after a price or stock change is the freshness problem we tear down separately in AI trained on your catalog . This post is its scale-axis sibling, and the two failures stack on a large, fast-moving catalog.
When one query now means four thousand products
A query like “black case” maps to three products at 1,000 SKUs and to roughly four thousand at 1,000,000. Ambiguity that was harmless at small scale becomes the dominant failure at large scale, and a search box alone cannot resolve it.
The fix is not a better ranker. It is a single conversation turn that asks what the shopper actually meant.
This is where the catalog manufactures ambiguity faster than ranking can absorb it. At three matches a shopper just scans.
At four thousand, phone cases and camera cases and watch cases and guitar cases all match the same two words, and no ranking signal in the world knows which one is in the shopper’s head. Search opens the fan; only a question closes it.
- One clarifying turn (“a case for what?”) collapses four thousand candidates to the handful the shopper would buy.
- 23+ languages compound the problem, because the same ambiguity recurs in every language the store sells in, with automatic detection deciding which one the shopper is using.
- A search-only box cannot ask the question, which is the structural ceiling.
That is why combined AI Search + Chatbot is an architecture, not a bundle of two features sold together. The search retrieves; the chat disambiguates; the same live index serves both.
The full structural case lives in the AI Search and Chatbot pillar , and live-state reads are what let the resolved answer reflect current price and stock rather than a snapshot. That live read is this post’s time-axis counterpart: it has a latency budget of its own , and where those milliseconds go is a separate teardown. Whether any change to retrieval actually lifted recall or quietly regressed it is the correctness axis, and catching that before shoppers do is the job of an offline retrieval eval harness .
What this doesn’t catch
These four axes are not the whole story, and the numbers carry conditions. The recall band (0.5 to 0.95) is general ANN literature on benchmark vector sets, not a Shoply measurement at 1M, and the exact thresholds shift with the embedding model, vertical, and query mix.
A few caveats before the takeaway:
- Below ~100,000 SKUs, most of this never fires. A store with a few thousand products should not re-architect anything; approximate retrieval there behaves close to exact.
- We left some modes out (filtering interactions with recall, multimodal queries, freshness under heavy write load) because they did not fit one diagram each.
- Treat the four axes as first-and-hardest, not as a closed set.
Thanks to the engineering reviewers who pushed back on the recall-cliff framing and kept the methodology line honest. If you are running a large Shopify catalog and want to compare notes on where your own retrieval starts to slip, we would genuinely like to hear about it.
Frequently asked questions
Does AI product search actually work for a million-product Shopify catalog?
Yes, but only if the retrieval layer is built for it. Exact search holds perfect recall but its cost grows with the catalog, so at scale you switch to an approximate index where recall drops to roughly 0.5 to 0.95 at a fixed latency budget. Shoply supports catalogs of 1M+ products and is built to hold recall as the catalog grows rather than trade it away silently.
Why does my AI search get less accurate as I add products?
Two effects stack. Near-identical variant SKUs crowd the same region of embedding space so similarity stops discriminating, and the long tail of new products gets thin interaction signal so its embeddings stay weak and rarely surface. Both get worse as the catalog grows, which is why a bigger catalog can feel less searchable per product.
At what catalog size do these retrieval failures start?
Roughly above 100,000 SKUs. Below that, approximate retrieval behaves close to exact search and the four failure modes rarely fire, so a small catalog usually does not need to re-architect anything. The effects become hard to ignore as the catalog approaches and passes a million products.
Can a chatbot fix large-catalog search ambiguity?
Yes. When one query matches thousands of products, no ranking signal can pick the one the shopper meant, but a single clarifying question can. That is why combined AI Search and Chatbot over one live index resolves ambiguity that a search box alone structurally cannot.
If you are about to cross six figures of SKUs
If your catalog is heading past a hundred thousand products and you want a second set of eyes on where retrieval starts to slip, Shoply AI runs combined AI Search and a chatbot over one live index, supports catalogs of 1M+ products, and learns the catalog with zero setup.
- See it: Shopify listing at apps.shopify.com/shopping-assistant-by-shoplyai , live demo at demo.shoplyai.ai .
- Go deeper: the structural argument in the AI Search and Chatbot pillar , and the broader AI search for Shopify landscape.
- Next step: how to add AI search to a Shopify store .
- The stack around it: where search and chat sit among the 5 best AI automation tools for Shopify in 2026 , tier ladders priced.
Happy scaling.